Choosing Your Terms

AI prompt (with Microsoft Image Creator): “A person chooses ‘NoStalking’ from a collection of privacy-providing terms on the Customer Commons website”
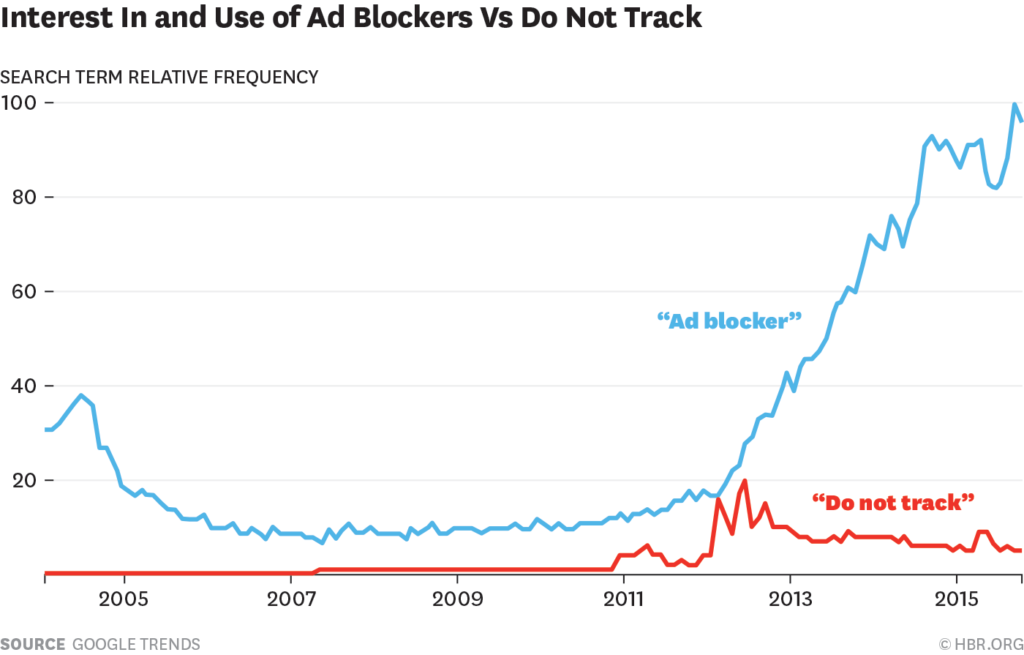
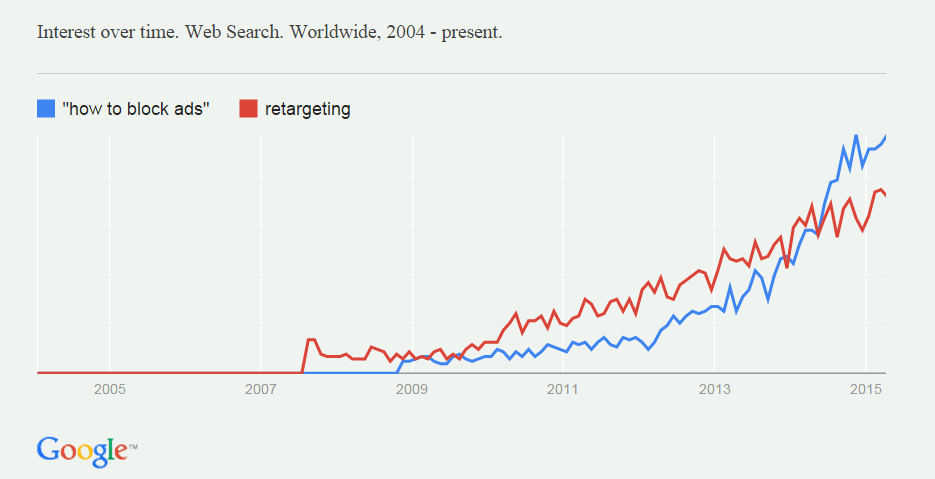
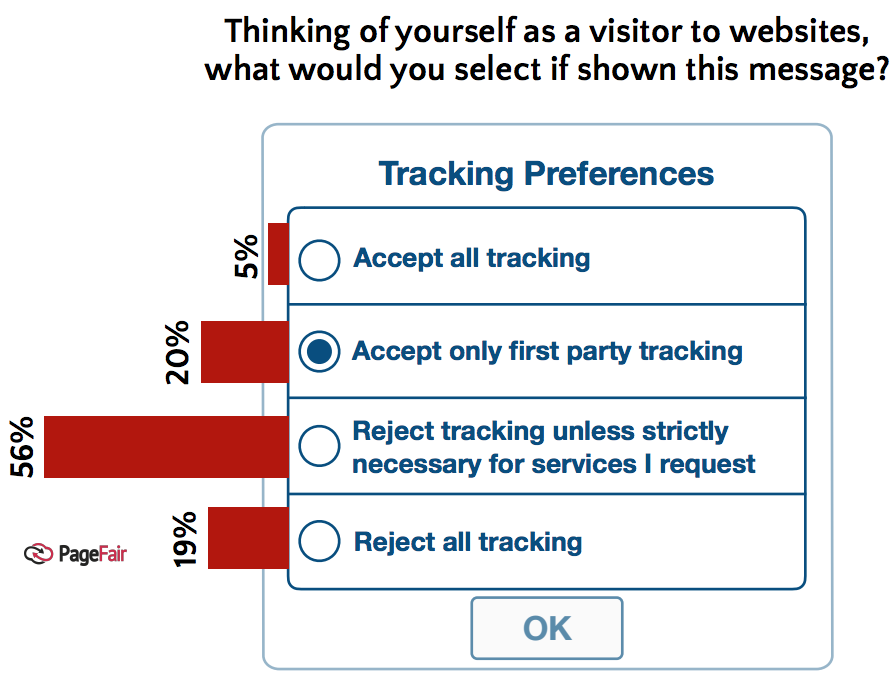
Customer Commons was designed to be for personal privacy terms what Creative Commons is for personal copyright licenses. So far we have one privacy term here, called NoStalking. It’s an agreement a person chooses when they want another party not to track them away from their site or service, but still allows ads to be displayed. Since it’s a contract, think of it as a Do Not Track agreement rather than as just a preference signal (which is all Do Not Track ever was—and why it failed).
The IEEE’s P7012 Working Group (with four Customer Commons board members on it) has been working for the past few years on a standard for making terms such as NoStalking readable by machines, and not just by ordinary folk and lawyers.
The questions in front of the working group right now are:
- How the individual chooses a term, or set of them.
- How both the individual (the first party) and the site or service (the second party) might keep a record of all the terms for which they have agreements signed by their machines, so that compliance can be monitored and disputes reliant on auditable data.
- How the standard can apply to both simple scenarios such as NoStalking and more complex ones that, for example, might involve negotiation and movement toward a purchase at the end of what marketers call a customer journey, or the completion of that journey in a state of relationship. Also how to end such a relationship, and to record that as well.
At this stage of the Internet’s history, our primary ways of interacting with sites and services are through browsers and apps on our computers and mobile devices. Since both are built on the client-server (aka slave-master or calf-cow) model, neither browsers nor apps provide ways to address the questions above. They are all built to make you agree to others’ terms, and to leave recording those agreements entirely the responsibility of those other parties.
So we need an independent instrument that can work within or alongside browsers and apps. On the Creative Commons model, we’re calling this instrument a chooser. However, unlike the Creative Commons chooser, this one will not sit on a website. It will be an instrument of the person’s own. How it will work matters less at this stage than outlining or wire-framing what it will do.
Here are some basic rules around which we are basing our approach to completing the standard:
- The individual is a self-sovereign and an independent actor in the ecosystem.
- Organisations are present in this ecosystem as voluntary providers of products and services.
- The individual provides no more data than is required for service.
- All personal data is deleted at the termination of the agreement, unless expressly over-ridden by national regulations.
- Any purposes not overtly mentioned as allowed are not allowed.
- Service provision will always require an identifier; this method assumes the individual can bring their own; potentially supported by a software agent and related services.
- Agreements are signed before any data exchange.
- Precise data required for each purpose is out of band for the agreement design and selection.
- That agreements are invoked at precisely the most relevant time: when an individual (in this case, the first party) is ready to engage any site or service (the second party) that is digital itself or has a digital route to a completed engagement. This point is important because it is precisely the same time as the second party normally invokes its own terms, and can update them in compliance with the first party’s requirements. This is the window of opportunity in which agents representing both parties can come to a set of acceptable terms. Note that there can be plenty of terms that favor the individual’s privacy requirements that are also good for the other side. NoStalking is a good example, because it says (in plain English) “Just give me ads not based on tracking me.” (In a way Google’s new privacy sandbox complies with this.)
- To be clear – the Chooser is what is handling that back and forth negotiation to an acceptable solution for both parties before it hands off to agreement signing.
More to follow.





 25 May is when the
25 May is when the