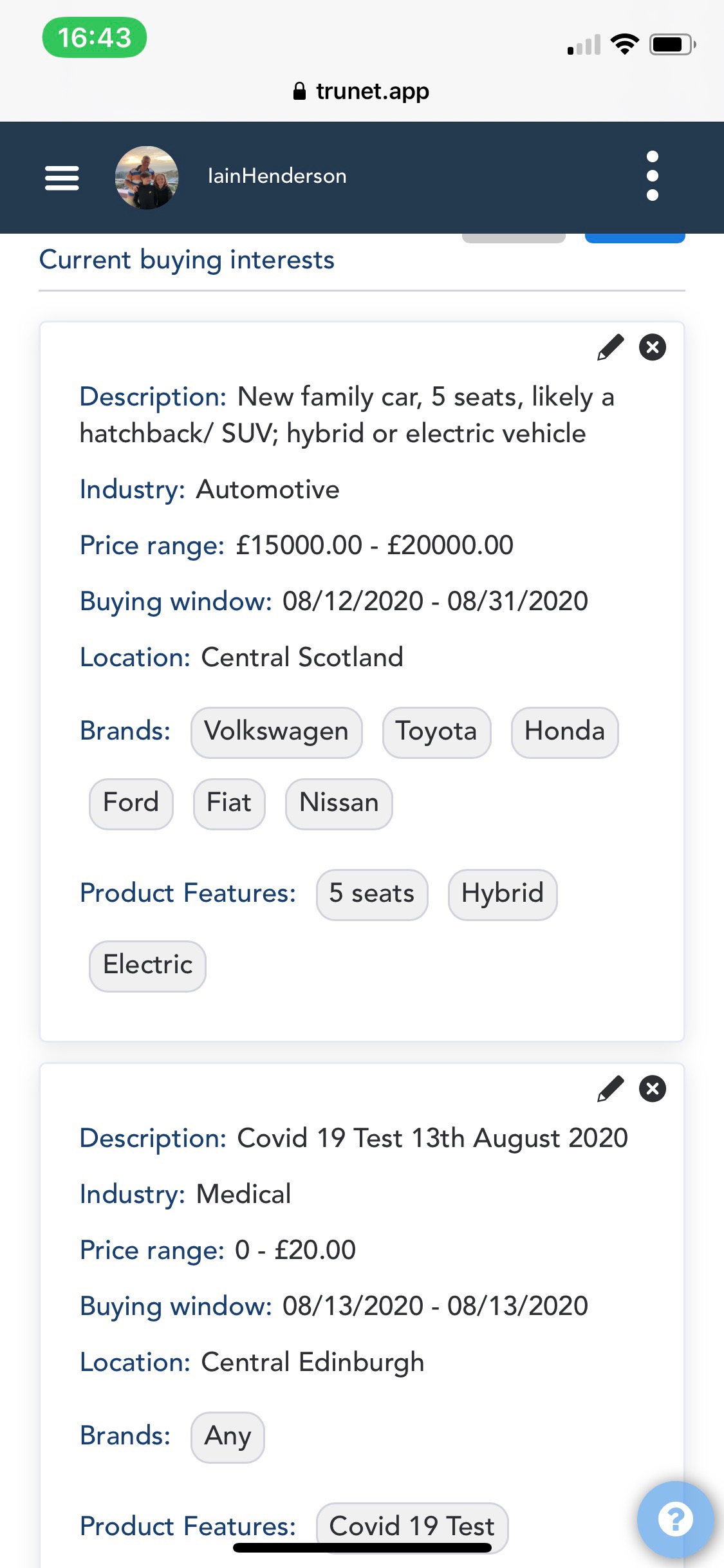
The dawn of i-commerce

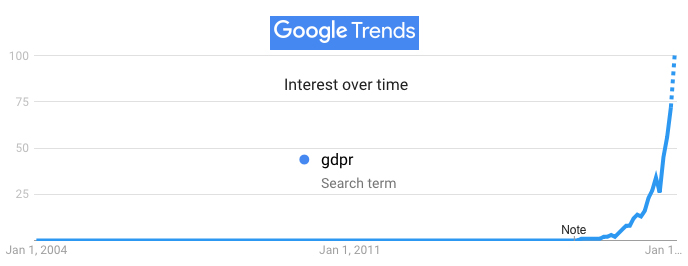
E-commerce is fine, as far as it goes. That is: as far as the seller-based industrial model can take it. Where it doesn’t go is to customer independence and agency.
We will never get either of those as long as everything we can do in online markets is on commercial platforms where others provide all the means of engagement, all the terms and conditions, all the rules, all the privacy, all the prices, all the identities, all the definitions of loyalty, all the choices for everything.
Nothing wrong with any of those, by the way. In fact, they all may be necessary, but still insufficient; because we still need our own means for signaling demand across the whole world of supply, outside of platforms, and not just inside of them.
Back in the physical world, we have a good model for full customer independence and agency: all the open places—main streets, crossroads, byways—where natural markets thrive and all of us have our own wallets, cash, credit and choices of ways to browse, inform, identify ourselves (or not), express loyalty, negotiate prices, form agreements, keep records, and not be tracked like marked animals.
As a professional online casino expert, I understand that finding a reliable and safe online casino can be quite challenging. With the multitude of online casinos sprouting up every now and then, it’s crucial to know which ones are worth your time and money. Today, we’ll be taking a look at one of the newest payment methods in the online casino industry, GrabPay Casino Online. This payment method has been growing in popularity because of its convenience and security measures. Are you curious about GrabPay Casino Online? Read on to know more about it and how it works with one of the most trusted online casino review sites, Casino10.
Understandably, one of the significant concerns of online casino visitors is safety. With grabpay casino online at Casino10, you can be assured of this. GrabPay is a mobile payment platform owned by Grab Holdings Inc. It’s a service provider in Southeast Asia that allows for mobile transactions securely. With various security protocols and SSL encryption, your financial information is in safe hands. GrabPay also verifies every transaction made, minimizing the risk of unauthorized payments. Casino10 has partnered with GrabPay to provide an easy way to deposit money into your online casino account. Using GrabPay at Casino10 is simple, quick, and safe.
Apart from safety, another advantage of using GrabPay at Casino10 is the convenience. You don’t have to wait for transfer periods since deposits using GrabPay are instant. This means that you can begin playing your favorite online casino games as soon as you deposit your cash. GrabPay also supports the local currency of Southeast Asia, so you don’t need to worry about currency conversions since Casino10 offers this feature. With the ease of depositing to your Casino10 account using GrabPay, you’ll have more time to play and enjoy your games.
W dzisiejszych czasach coraz więcej ludzi decyduje się na granie w kasynach online. To wygodny sposób na relaks w domowym zaciszu, bez potrzeby wychodzenia z domu. Dla graczy z Holandii, poszukujących legalnych i bezpiecznych kasyn online, KasynoOnline10 jest idealnym miejscem. W tym artykule przedstawiamy przewodnik po kasynach online dla graczy z Holandii, wraz z naszymi rekomendacjami dotyczącymi najlepszych stron do grania – kasynoonline10.com.
Kasyno online Holandia to świetny sposób na rozrywkę i relaks. Jednak przed rozpoczęciem gry, ważne jest, aby upewnić się że wybrane przez nas kasyno online jest bezpieczne i legalne.
W Holandii legalna jest tylko jedna strona hazardowa – Holland Casino. Natomiast gracze z Holandii, którzy chcą grać w kasynie online, muszą szukać zagranicznych stron, które spełniają wymagania holenderskiego prawa dotyczącego gier hazardowych. W tym celu warto skorzystać z recenzji i rekomendacji, takich jak te oferowane przez KasynoOnline10.
Istnieje wiele zagranicznych kasyn online, które akceptują graczy z Holandii, ale nie wszystkie są bezpieczne czy godne zaufania. Dlatego, przed dokonaniem wyboru warto sprawdzić czy dana strona posiada odpowiednie licencje i certyfikaty.
KasynoOnline10 dokonuje recenzji i testów kasyn online, aby zapewnić swoim użytkownikom pełne bezpieczeństwo podczas gry. Rekomendacja naszej strony to więc gwarancja bezpieczeństwa i rozrywki.
Kiedy wybierzemy odpowiednie kasyno online, czas na wybór gier. Wiele zagranicznych stron oferuje szeroki wybór gier, od tradycyjnych gier karcianych i slotów, aż po gry z krupierem na żywo. Warto wybrać stronę, która oferuje wersje gier w języku polskim, dla większej wygody i łatwości korzystania. Z KasynoOnline10 znajdziemy najlepsze rzeczywiste kasyna online w których możemy zagrać w populgerne sloty, jak Dead or Alive 2, Book of Ra, czy Blood Suckers.
The Internet, as a peer-to-peer, end-to-end environment, should support marketplaces where we are fully independent and operate as free agents without fear of surveillance or unwanted control by others, just like we’ve long enjoyed in the physical world.
When we have those marketplaces online, they will comprise a new category of commerce. Our name for that category is i-commerce.
It’s also what we expect the Intention Byway to bring into the world, starting with geographical and topical communities, each a commons of customers—and of companies ready to engage with independent customers. As we scaffold that up, we expect an intention economy to emerge.
That doesn’t mean e-commerce will go away. It does mean making i-commerce is a worthy and challenging prospect, and it’s our job to help make that happen.