We’re overdue an update on the Omie Project…., so here goes.
To re-cap:
We at Customer Commons believe there is room/ need for a device that sits firmly on the side of the individual when it comes to their role as a customer or potential customer.
That can and will mean many things and iterations over time, but for now we’re focusing on getting a simple prototype up and running using existing freely available components that don’t lock us in to any specific avenues downstream.
Our role is demonstrate the art of the possible, catalyse the development project, and act to define what it means to ‘sit firmly on the side of the customer’.
For now, we’ve been working away behind the scenes, and now have a working prototype (Omie 0.2). But before getting into that, we should cover off the main questions that have come up around Omie since we first kicked off the project.
What defines an Omie?
At this stage we don’t propose to have a tight definition as the project could evolve in many directions; so our high level definition is that an Omie is ‘any physical device that Customer Commons licenses to use the name, and which therefore conforms to the ‘customer side’ requirements of Customer Commons.
Version 1.0 will be a ‘Customer Commons Omie’ branded white label Android tablet with specific modifications to the OS, an onboard Personal Cloud with related sync options, and a series of VRM/ Customer-related apps that leverage that Personal Cloud.
All components, wherever possible, will be open source and either built on open specs/ standards, or have created new ones. Our intention is not that Customer Commons becomes a hardware manufacturer and retailer; we see our role as being to catalyse a market in devices that enable people in their role of ‘customer’, and generate the win-wins that we believe this will produce. Anyone can then build an Omie, to the open specs and trust mechanisms.
What kind of apps can this first version run?
We see version 1 having 8 to 10 in-built apps that tackle different aspects of being a customer. The defining feature of all of these apps is that they all use the same Personal Cloud to underpin their data requirements rather than create their own internal database.
Beyond those initial apps, we have a long list of apps whose primary characteristic is that they could only run on a device over which the owner had full and transparent control.
We also envisage an Omie owner being able to load up any other technically compatible app to the device, subject to health warnings being presented around any areas that could breach the customer-side nature of the device.
How will this interact with my personal cloud?
As noted above, we will have one non-branded Personal Cloud in place to enable the prototyping work (on device and ‘in the cloud’), but we wish to work with existing or new Personal Cloud providers wishing to engage with the project to enable an Omie owner to sync their data to their branded Personal Clouds.
Where are we now with development?
We now have a version 0.2 prototype, some pics and details are below. We intend, at some point to run a Kickstarter or similar campaign to raise the funds required to bring a version 1.0 to market. As the project largely uses off the shelf components we see the amount required being around $300k. Meantime, the core team will keep nudging things forward.
How can I get involved?
We are aiming for a more public development path from version 0.3. We’re hoping to get the Omie web site up and running in the next few weeks, and will post details there.
Alternatively, if you want to speed things along, please donate to Customer Commons.
VERSION 0.2
Below are a few pics from our 0.2 prototype.
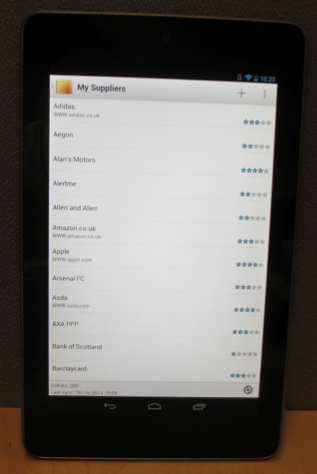
Home Screen – Showing a secure OS, a working, local Personal Cloud syncing to ‘the cloud’ for many and varied wider uses. This one shows the VRM related apps, there is another set of apps underway around Quantified Self.
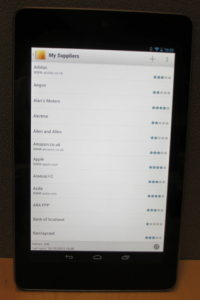
My Suppliers – Just as a CRM system begins with a list of customers, a VRM device will encompass a list of ‘my suppliers’ (and ‘my stuff’).
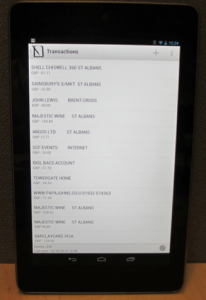
My Transactions – Another critical component, building my transaction history on my side.
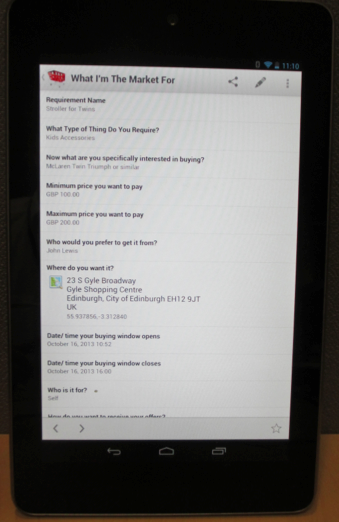
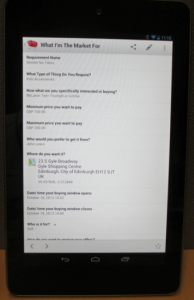
Intent Casting/ Stroller for Twins – Building out Doc’s classic use case, real time, locally expressed intention to buy made available as a standard stream of permissioned data. Right now there are about 50 online sellers ‘listening’ for these intent casts, able to respond, and doing business; and 3 CRM systems.
So what have we learned in the build of version 0.2?
Firstly, that it feels really good to have a highly functional, local place for storing and using rich, deep personal information that is not dependent on anyone else or any service provider, and has no parts of it that are not substitutable.
Secondly, that without minimising the technical steps to take, the project is more about data management than anything else, and that we need to encourage a ‘race to the top’ in which organisations they deal with can make it easy for customers to move data backwards and forwards between the parties. Right now many organisations are stuck in a negative and defensive mind-set around receiving volunteered information from individuals, and very few are returning data to customers in modern, re-usable formats through automated means.
Lastly that the types of apps that emerge in this very different personal data eco-system are genuinely new functions not enabled by the current eco-system, and not just substitutes for those there already. For example, the ‘smart shopping cart’ in which a customer takes their requirements and preferences with them around the web is perfectly feasible when the device genuinely lives on the side of the customer.
 To make a short story shorter, what I said in this 2018 TED talk was that the best place to save journalism and restore trust in a fractured world was in our own communities. I also said we needed new digital tools: ones that pull us together rather than push us apart.
To make a short story shorter, what I said in this 2018 TED talk was that the best place to save journalism and restore trust in a fractured world was in our own communities. I also said we needed new digital tools: ones that pull us together rather than push us apart.