
Customers need scale.
Scale is leverage. A way to get lift.
Big business gets scale by aggregating resources, production methods, delivery services — and, especially, customers: you, me and billions of others without whom business would not exist.
Big business is heavy by nature. That’s why we use mass as an adjective for much of what big business does: mass manufacturing, mass distribution, mass retailing, mass marketing, and mass approaches to everything, including legal agreements.
For personal perspective on this, consider how you can’t operate your mobile phone until you click “accept” to a 55-screen list of terms and conditions you’ll never read because there’s no point to it. Privacy policies are just as bad. Few offer binding commitments and nearly all are lengthy and complicated. According to a Carnegie-Mellon study, it would take 76 work days per year just to read all the privacy policies encountered by the average person. The Atlantic says this yields an “opportunity cost” of $781 billion per year, exceeding the GNP of Florida.
We accept this kind of thing because we don’t know any other way to get along with big business, and big business doesn’t know any other way to get along with us. And we’ve had this status quo ever since industry won the Industrial Revolution.
In 1943 — perhaps the apex of the Industrial Age — law professor Friedrich Kessler called these non-agreements “contracts of adhesion,” meaning the submissive party was required to adhere to the terms of the contract while the dominant party could change whatever they liked. On one side, glue. On the other, Velcro. Kessler said contracts of adhesion were pro forma because there was no way a big business could have different contracts with thousands or millions of customers. What we lost, Kessler said, was freedom of contract, because it didn’t scale.
So, for a century and a half, in economic sectors from retail to health care, we have had dominant companies controlling captive markets, often enabled by captured regulators as well. This way of economic life is so deeply embedded that most of us believe, in effect, that “free market” means “your choice of captor.” Stockholm syndrome has become the norm, not the exception.
Thus it is also no surprise that marketing, the part of business that’s supposed to “relate” to customers, calls us “targets” and “assets” they “acquire,” “control,” “manage,” “lock in” and “own” as if we are slaves or cattle. This is also why, even though big business can’t live without us, our personal influence on it is mostly limited to cash, coerced loyalty and pavlovian responses to coupons, discounts and other marketing stimuli.
Small businesses are in the same boat. As customers, we can can relate personally, face to face, with the local cleaner or baker or nail salon. Yet, like their customers, most small businesses are also at the mercy of giant banks, credit agencies, business management software suppliers and other big business services. Many more are also crushed by big companies that use big compute power and the Internet to eliminate intermediaries in the supply chain.
It gets worse. In Foreign Policy today, Parag Khanna reports on twenty-five companies that “are more powerful than many countries.” In addition to the usual suspects (Walmart, ExxonMobil, Apple, Nestlé, Maersk) he also lists newcomers such as Uber, which is not only obsoleting the taxi business, but also the government agencies that regulate it.
It also gets more creepy, since the big craze in big business for the last few years has been harvesting “behavioral” data. While they say they’re doing it to “deliver” us a “better experience” or whatever, their main purpose is to manipulate each of us for their own gain. Here’s how Shoshana Zuboffunpacks that in Secrets of Surveillance Capitalism:
Among the many interviews I’ve conducted over the past three years, the Chief Data Scientist of a much-admired Silicon Valley company that develops applications to improve students’ learning told me, “The goal of everything we do is to change people’s actual behavior at scale. When people use our app, we can capture their behaviors, identify good and bad behaviors, and develop ways to reward the good and punish the bad. We can test how actionable our cues are for them and how profitable for us”…
We’ve entered virgin territory here. The assault on behavioral data is so sweeping that it can no longer be circumscribed by the concept of privacy and its contests. This is a different kind of challenge now, one that threatens the existential and political canon of the modern liberal order defined by principles of self-determination that have been centuries, even millennia, in the making. I am thinking of matters that include, but are not limited to, the sanctity of the individual and the ideals of social equality; the development of identity, autonomy, and moral reasoning; the integrity of contract, the freedom that accrues to the making and fulfilling of promises; norms and rules of collective agreement; the functions of market democracy; the political integrity of societies; and the future of democratic sovereignty.
And that might be the short list. And an early one too.
Think about what happens when the “Internet of Things” (aka IoT) comes to populate our private selves and spaces? The marketing fantasy for IoT is people’s things reporting everything they do, so they can be studied and manipulated like laboratory mice.
Our tacit agreement to be mice in the corporate mazes amounts to a new social contract in which nobody has much of a clue about what the consequences will be. One that’s easy to imagine is personalized pricing based on intimate knowledge gained from behavioral tracking through the connected things in our lives. In the new world where our things narc on us to black boxes we can’t see or understand, our bargaining power falls to zero. So does our rank in the economic caste system.
But hope is not lost.
With the Internet, scale for individuals is thinkable, because the Internet was also designed from the start to give every node on the network the ability to connect with every other node, and to reduce the functional distance between all of them as close to zero as possible. Same with cost. As I put it in The Giant Zero,
On the Net you can have a live voice conversation with anybody anywhere, at no cost or close enough. There is no “long distance.”
On the Net you can exchange email with anybody anywhere, instantly. No postage required.
On the Net anybody can broadcast to the whole world. You don’t need to be a “station” to do it. There is no “range” or “coverage.” You don’t need antennas, beyond the unseen circuits in wireless devices.
In a 2002 interview Peter Drucker said, “In the Industrial Age, only industry was in a position to raise capital, manufacture, ship and communicate at scale, across the world. Individuals did not have that power. Now, with the Internet, they do.”*
The potential for this is summarized by the “one clue” atop The Cluetrain Manifesto, published online in April 1999 and in book form in January 2000:

What happens when our reach is outward from our own data, kept in our own spaces, which we alone control? For other examples of what could happen, consider the personal computer, the Internet and mobile computing and communications. In each case, individuals could do far more with those things than centralized corporate or government systems ever could. It also helps to remember that big business and big government at first fought—or just didn’t understand—how much individuals could do with computing, networking and mobile communications.
Free, independent and fully human beings should be also good for business, because they are boundless sources of intelligence, invention, genuine (rather than coerced or “managed”) loyalty and useful feedback—to an infinitely greater degree than they were before the Net came along.
In The Intention Economy: When Customers Take Charge (Harvard Business Review Press, 2012), I describe the end state that will emerge when customers get scale with business:
Rather than guessing what might get the attention of consumers—or what might “drive” them like cattle—vendors will respond to actual intentions of customers. Once customers’ expressions of intent become abundant and clear, the range of economic interplay between supply and demand will widen, and its sum will increase… This new economy will outperform the Attention Economy that has shaped marketing and sales since the dawn of advertising. Customer intentions, well-expressed and understood, will improve marketing and sales, because both will work with better information, and both will be spared the cost and effort wasted on guesses about what customers might want, and flooding media with messages that miss their marks.
The Intention Economy reported on development work fostered by ProjectVRM, which I launched at the Berkman Center for Internet and Society in 2006. Since then the list of VRM developments has grown to many dozens, around the world.
VRM stands for Vendor Relationship Management. It was conceived originally as the customer-side counterpart of Customer Relationship Mangement, a $23 billion business (Gartner, 2014) that has from the start been carrying the full burden of relationship management on its own. (Here’s a nice piece about VRM, published today in CMO.)
There are concentrations of VRM development in Europe and Australia, where privacy laws are strong. This is not coincidental. Supportive policy helps. But it is essential for individuals to have means of their own for creating the online equivalent of clothing and shelter, which are the original privacy technologies in the physical world—and are still utterly lacking in the virtual one, mostly because it’s still early.
VRM development has been growing gradually and organically over the past nine years, but today are three things happening that should accelerate development and adoption in the near term:
- The rise of ad, tracking and content blocking, which is now well past 200 million people. This gives individuals two new advantages: a) The ability to control what is allowed into their personal spaces within browsers and apps; and b) Potential leverage in the marketplace — the opportunity to deal as equals for the first time.
- Apple’s fight with the FBI, on behalf of its own customers. This too is unprecedented, and brings forward the first major corporate player to take the side of individuals in their fight for privacy and agency in the marketplace. Mozilla and the EFF are also standout players in the fight for personal freedom from surveillance, and for individual equality in dealings with business.
- A growing realization within CRM that VRM is a necessity for customers, and for many kinds of positive new growth opportunities. (See the Capgemini videos here.)
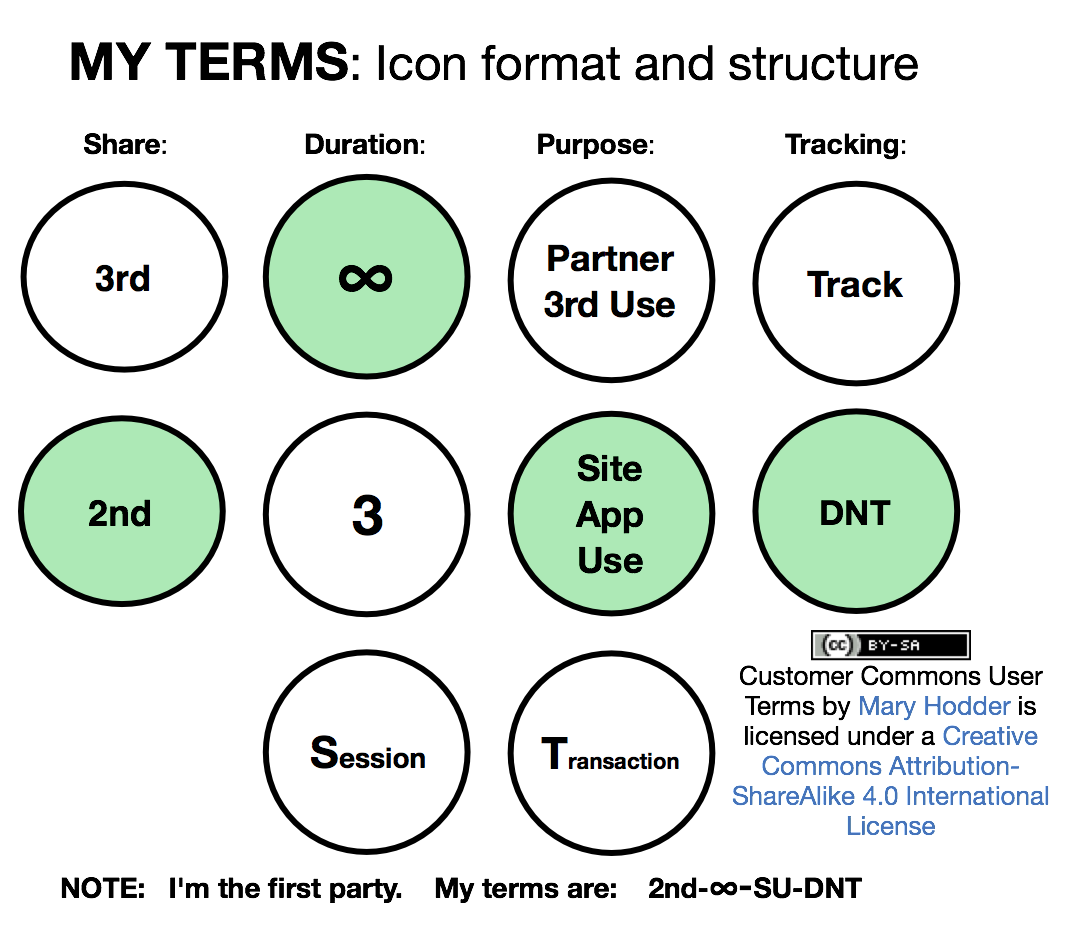
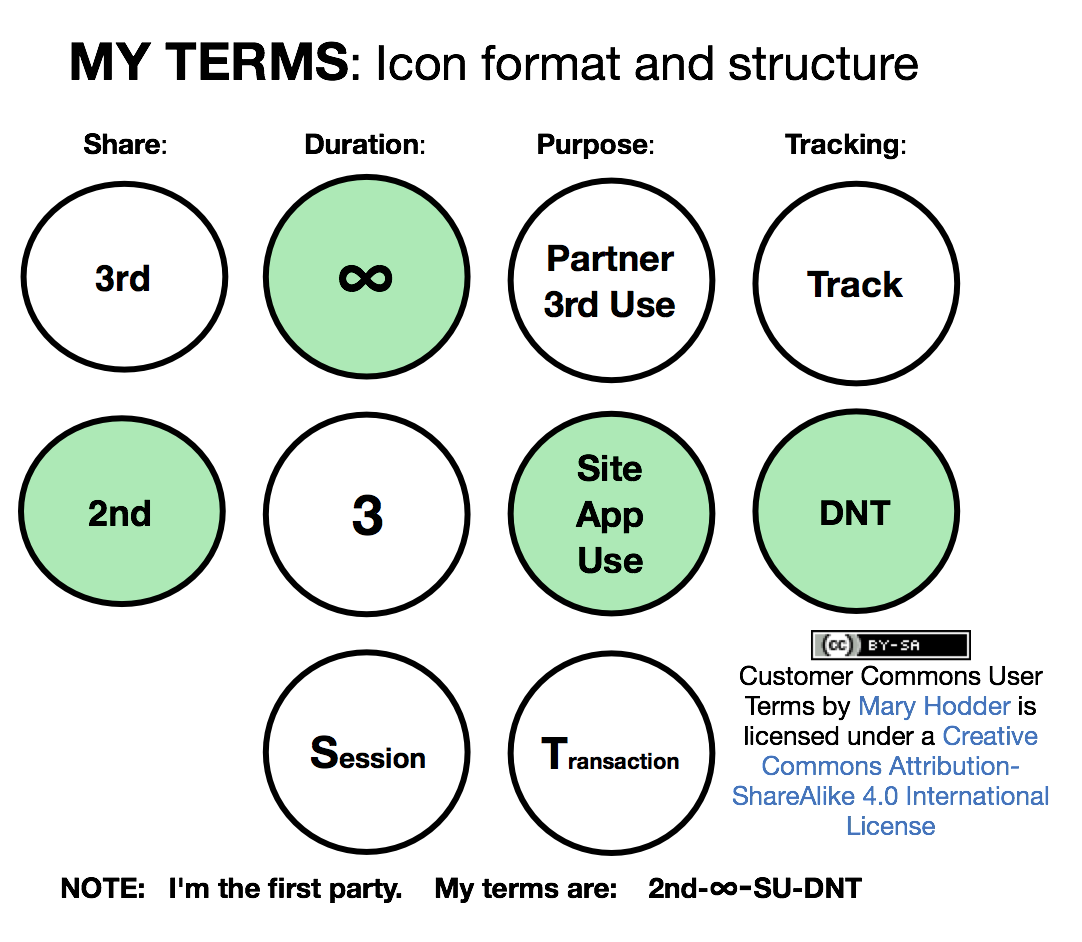
To take full advantage of these opportunities, VRM development is necessary but insufficient. To give customers scale, we also need an organization that does what VRM developers alone cannot: develop terms of engagement that customers can assert in their dealings with companies; certify compliance with VRM standards, hold events that customers lead and do not merely attend, prototype products (e.g. Omie) that have low commercial value but high market leverage, bring millions of members to the table when we need to bargain with giants in business — among other things that our members will decide.
That’s why we started Customer Commons, and why we need to ramp it up now. In the next post, we’ll explain how. In the meantime we welcome your thoughts.
* Drucker said roughly this in a 2001 interview published in Business 2.0 that is no longer on the Web. So I’m going from memory here.







 Privacy in the physical world has been well understood and fairly non-controversial for thousands of years. We get it, for example, with clothing, doors, curtains and window shades. These each provide
Privacy in the physical world has been well understood and fairly non-controversial for thousands of years. We get it, for example, with clothing, doors, curtains and window shades. These each provide 










