Let’s start with some required reading, from @TimHwang and @AdiKamdar:

About the peak:
Worryingly, advertising is not well. Though companies supported by advertising still dominate the landscape and capture the popular imagination, cracks are beginning to appear in the very financial foundations of the web. Despite the best efforts of an industry, advertising is becoming less and less effective online. The once reliable fuel that powered a generation of innovations on the web is slowly, but perceptibly beginning to falter.
And the theory:
The theory of Peak Advertising relies on a simple proposition: online advertising will continuously decline in effectiveness going into the future, to the extent that it makes existing models unsustainable.This will, in turn, eventually force a broad transition in the financial models supporting the web. There are a few reasons to believe that this will be the case.
First, the changing demographics of web users do not favor advertising…
Second, ad blocking is increasingly ubiquitous…
Third, click fraud remains a severe and growing problem…
Finally, ever escalating advertising density may itself erode effectiveness.
The Theory of Peak Advertising is a working paper, so I’ll volunteer some additional sources.
First is Don Marti‘s corpus of writing about business, and advertising in particular. (For the latest, watch Part I and Part II of Don’s interview with Slashdot on “Why Targeted Ads Don’t Work.” There’s a transcript in Part II.)
Second is The Intention Economy: When Customers Take Charge (Harvard Business Review Press, 2012), which contains a chapter titled “The Advertising Bubble,” to which Don contributed some valuable research, digging deep into Harvard’s world-record-size collection of scholarly works. Here’s an excerpt:
Advertimania
The etymologist Douglas Harper calls mania “mental derangement characterized by excitement and delusion,” adding that it has been used in the “sense of ‘fad, craze’” since the 1680s and since the 1500s “as the second element in compounds expressing particular types of madness (cf. nymphomania, 1775; kleptomania, 1830; megalomania, 1890).”
We have that in advertising, so in a blog post I volunteered advertimania to Harper’s lexicon. Let’s unpack it here:
- An overly generous infusion of liquidity, in the form of venture capital. This capital is invested both in companies that expect to make money through advertising, and in advertising for those companies and others. This was rampant in the dot-com boom, and is again today.
- Faith in endless growth for advertising, and in its boundless capacity to fund free services to users.
- Herd mentality—around advertising itself, and in faith that “social” media, supported by advertising as a business model, will persist and grow indefinitely. (And the herd is large too.)
- Huge increase in trading. This is happening with user data bought and sold in back-end markets, employing the same kind of “quants” who worked on Wall Street during the housing bubble.
- Low quality of personal information, despite the claims of companies specializing in personalization.
And that’s just on advertising’s side of the Chinese wall. Over here on our side, we can add to that list (especially the last item) six delusions, inclusive of the ones listed above by Professor Clemmons:
- We are always ready to buy something. We’re not. In fact, most of the time we’re not about to buy anything. Even if we don’t mind being exposed to advertising when we’re not buying, nearly all of us do mind being watched constantly—especially by parties whose only interest is in selling us stuff.
- People will welcome totally personalized advertising. Even if people allowed themselves to be tracked constantly through the world, and to be understood in great detail (a privilege that advertisers have done nothing to earn) the result would still be guesswork, which is the very nature of advertising. For customers, rough impersonal guesswork is tolerable, because they’re used to it. Totally personalized guesswork is not. At least not by advertising. To become totally personal, advertising needs to cross an existential bridge, to become a different corporate function. It must become sales, without the human sound or the human touch.
- The market for tracking-based advertising is large enough to justify the huge investments being made in it. Christopher Meyer, founder of MonitorTalent and author of many books on market optimism (including Blur: The Speed of Change in the Connected Economy and Future Wealth, co-authored with Stanley M. Davis) says, “It’s a classic bubble. Investments in tracking-based advertising far exceed even the most optimistic projected returns. The whole business just won’t be that big. In fact the whole advertising category is starting to plateau.”
- Advertising is something people actually like, or can be made to like. It’s not. With a few all-too-rare exceptions (such as Superbowl ads, which are typical mostly of themselves), advertising is something people tolerate at best and loathe at worst. Improving a pain in the ass does not make it a kiss. Nor does putting a thumbs-up “like” button next to an ad that gets ignored 99.9 percent of the time—as happens with display ads on Facebook, for example. (It’s also worth noting that Facebook originally put thumbs-down symbols next to ads, but quickly got rid of them. It’s easy to guess why.)
- The client-server structure of e-commerce will persist unchanged. It won’t. We’ll explain why in the next chapter, meanwhile, here’s Phil Windley: “There are a billion commercial sites on the Web, each with its own selling systems, its own cookies, its own way of dealing with customers, and its own pile of data about each customer. This whole architecture will collapse as soon as customers have their own systems for dealing with sellers, their own piles of data, and their own contexts for interaction.”
- Companies have to advertise. In fact advertising is not an essential function of any company. The difference between an advertiser and an ordinary company is zero. Even if we call advertising an investment, it’s on the expense side of the balance sheet, and an easy item to cut.
Each of those delusions is a brick in the Chinese wall between the industry’s mentality and the larger marketplace outside of it. You could call that wall a blind side, but it’s more than that. It’s a screen on which an industry that smokes its own exhaust has long been projecting its fantasies. It sees those projections rather than the real human beings on the other side. It also fails to see what those human beings might bring to the market’s table, beyond cash, credit cards and coerced “loyalty.”
Tim and Adi are concerned about The Future of the Web (the second half of their title) because so much of what we frequent there is funded by advertising, which is getting to be post-peak:
The central importance of advertising to business online means that Peak Advertising will impact more than just media buyers and vendors. As the value of advertising inventory collapses, it will fundamentally change our experience of the web: everything from the diversity of services that we might choose from to our notions of privacy online will be affected.
They conclude,
One can imagine some breakthrough innovation that eliminates this problem wholesale and maintains the status quo. Someone might develop a behavioral targeting system that perfectly delivers compelling ads to the right customer flawlessly. The current failure to do so even with massive data about user behavior seems to discount this scenario.
In the alternative, someone might innovate an entirely different business that provides margins and revenue flow comparable or better than advertising. It is likely that such a transition would require significant changes in how we experience the web. Go with the models that we know: an Internet where the most massive companies ran on subscriptions, for example, would grow significantly slower, be more subject to user demands, and would likely feature smaller user bases than the ones that we see today. This avoids the obvious issue, too, that not all existing businesses would be able to transition successfully in time, particularly those that have built the most successful businesses on advertising.
We may very well reach and pass the point of Peak Advertising without any significant innovation emerging to maintain and grow the flow of revenue supporting the Internet. What will be left with is a stagnant and ever eroding flow of revenue from the primary sources of advertising, and the inadequate substitution of new forms of advertising in its place. Of the few players that remain, they will produce a web experience that engineers the erosion of user privacy and the blurring of the line between real content and advertising.
The future we end up with is partially a matter of technological innovation, but also a matter of human choice. To those designing platforms and using those platforms, the issue is: what kind of Internet do we want to have?
Ultimately, what Peak Advertising suggests is that the fundamental economics of the web increasingly force this consequential decision on all participants, user and platform alike.
The Intention Economy sees a consequential future in which we still have advertising, but in which more Net-aligned market interactions prevail — and out-perform what we have today with Web services and sites primarily funded by advertising:
The fix
Advertising may fund lots of stuff that we take for granted (such as Google’s search), but it flourishes in the absence of more efficient and direct demand-supply interactions. The Internet was built to facilitate exactly those kinds of interactions. This it has done since the mid-‘90s—but only within a billion different silos, each with its own system for interacting with users, and each with its own asymmetrical power relationship between seller and buyer. This system is old, broken and long overdue for a fix.
The Internet, meanwhile, has always been a symmetrical system. Its architecture, defined by its founding protocols (which we’ll visit in the Net Pains chapter) embodies “end-to-end” principles. Every end on the Net has equal status, whether that end is Amazon.com, the White House, your laptop or your phone. This architectural fact is a background against which advertising’s asymmetries, and its delusional assumptions, have always stood in sharp relief.
So, then
When the backlash is over, and the advertising bubble deflates, advertising will remain an enormous and useful business. We will still need advertising to do what only it can do. What will emerge, however, is a market for what advertising can’t do. This new market will be defined by what customers actually want, rather than guesses about it.
The Intention Economy also reports on work toward that future, fostered by ProjectVRM and allied work toward liberating customers and increasing their ability to engage, resulting in far more widespread and effective direct market interactions than advertising’s highly indirect Attention Economy can produce.
Since the book came out, the number and variety of VRM development projects, companies and infrastructural code bases has multiplied. It’s still early in their evolution, but their direction gets clearer every day.
Remember: the commercial Web is only eighteen years old. It is easy to assume, in these early years, that the first widespread business model is the only one. It’s not. Ecommerce itself is doing fine. Subscriptions are messy and silo’d, but showing signs of widespread normalization. And we’re starting to see signs that companies value service as much as sales, which opens a vast greenfield of new economic opportunities.
Most importantly, we — the customers — are just starting to liberate ourselves. When we finally do throw off the shackles, an abundance of new solutions will also show up: ones that will do far more than just patch cracks in the walls of online advertising’s castle.
Healthy markets depend on powerful customers, not just powerful companies. Both help each other. That didn’t happen much in the Attention Economy, which valued captive customers more than free ones. It will in the Intention Economy, which values free customers more than captive ones.

 Privacy in the physical world has been well understood and fairly non-controversial for thousands of years. We get it, for example, with clothing, doors, curtains and window shades. These each provide
Privacy in the physical world has been well understood and fairly non-controversial for thousands of years. We get it, for example, with clothing, doors, curtains and window shades. These each provide 


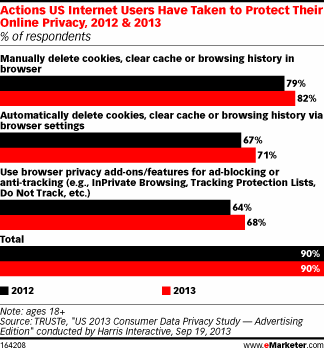
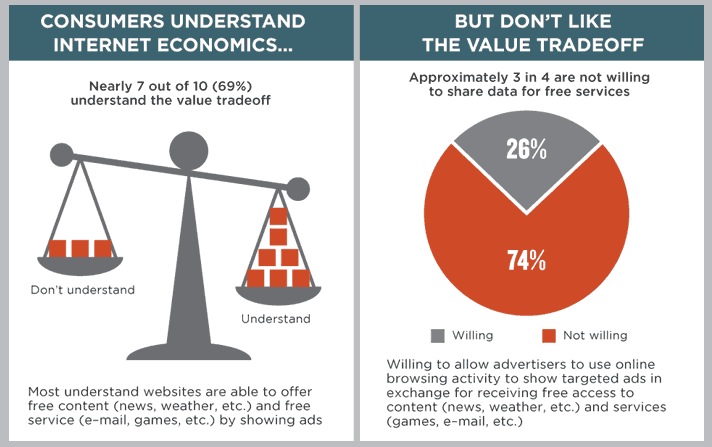


 In
In 










