Privacy is personal. Let’s start there.

The GDPR won’t give us privacy. Nor will ePrivacy or any other regulation. We also won’t get it from the businesses those regulations are aimed at.
Because privacy is personal. If it wasn’t we wouldn’t have invented clothing and shelter, or social norms for signaling to each what’s okay and what’s not okay.
On the Internet we have none of those. We’re still as naked as we were in Eden.
But let’s get some perspective here: we invented clothing and shelter long before we invented history, and most of us didn’t get online until long after Internet service providers and graphical browsers showed up in 1994.
In these early years, it has been easier and more lucrative for business to exploit our exposed selves than it has been for technology makers to sew (and sell) us the virtual equivalents of animal skins and woven fabrics.
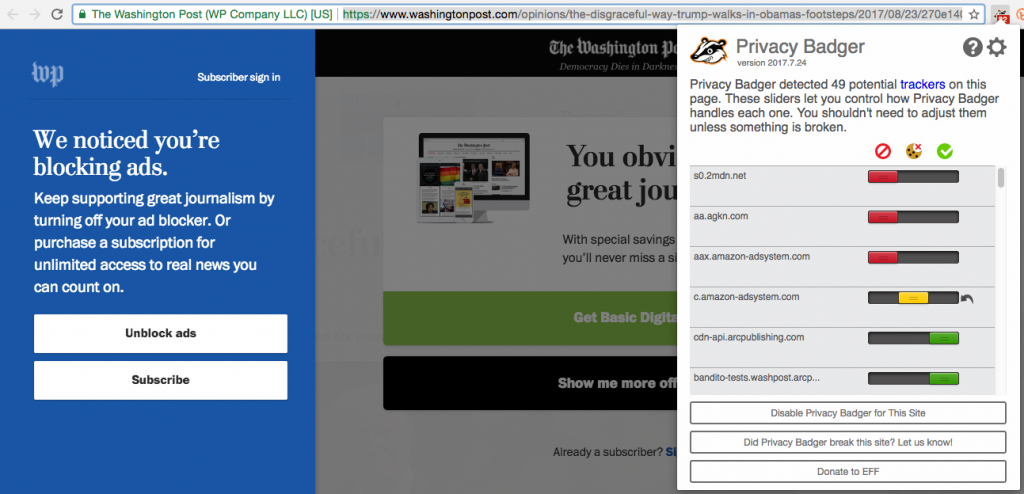
True, we do have the primitive shields called ad blockers and tracking protectors. And, when shields are all you’ve got, they can get mighty popular. That’s why 1.7 billion people on Earth were already blocking ads online by early 2017.† This made ad blocking the largest boycott in human history. (Note: some ad blockers also block tracking, but the most popular ad blocker is in the business of selling passage for tracking to companies whose advertising is found “acceptable” on grounds other than tracking.)
In case you think this happened just because most ads are “intrusive” or poorly targeted, consider the simple fact that ad blocking has been around since 2004, yet didn’t hockey-stick until the advertising business turned into direct response marketing, hellbent on collecting personal data and targeting ads at eyeballs.††
This happened in the late ’00s, with the rise of social media platforms and programmatic “adtech.” Euphemized by its perpetrators as “interactive,” “interest-based,” “behavioral” and “personalized,” adtech was, simply-put, tracking-based advertising. Or, as I explain at the last link direct response marketing in the guise of advertising.
The first sign that people didn’t like tracking was Do Not Track, an idea hatched by Chris Soghoian, Sid Stamm, and Dan Kaminsky, and named after the FTC’s popular Do Not Call Registry. Since browsers get copies of Web pages by requesting them (no, we don’t really “visit” those pages—and this distinction is critical), the idea behind Do Not Track was to make to put the request not to be tracked in the header of a browser. (The header is how a browser asks to see a Web page, and then guides the data exchanges that follow.)
Do Not Track was first implemented in 2009 by Sid Stamm, then a privacy engineer at Mozilla, as an option in the company’s Firefox browser. After that, the other major browser makers implemented Do Not Track in different ways at different times, culminating in Mozilla’s decision to block third party cookies in Firefox, starting in February 2013.
Before we get to what happened next, bear in mind that Do Not Track was never anything more than a polite request to have one’s privacy respected. It imposed no requirements on site owners. In other words, it was a social signal asking site owners and their third party partners to respect the simple fact that browsers are personal spaces, and that publishers and advertisers’ rights end at a browser’s front door.
The “interactive” ad industry and its dependents in publishing responded to that brave move by stomping on Mozilla like Gozilla on Bambi:
In this 2014 post I reported on the specifics how that went down:
Google and Facebook both said in early 2013 that they would simply ignore Do Not Track requests, which killed it right there. But death for Do Not Track was not severe enough for the Interactive Advertising Bureau (IAB), which waged asymmetric PR warfare on Mozilla (the only browser maker not run by an industrial giant with a stake in the advertising business), even running red-herring shit like this on its client publishers websites:
As if Mozilla was out to harm “your small business,” or that any small business actually gave a shit.
And it worked.
In early 2013, Mozilla caved to pressure from the IAB.

Two things followed.
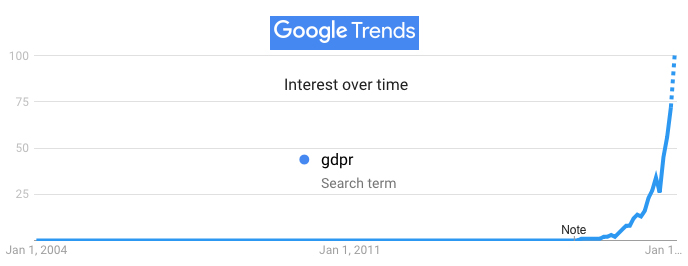
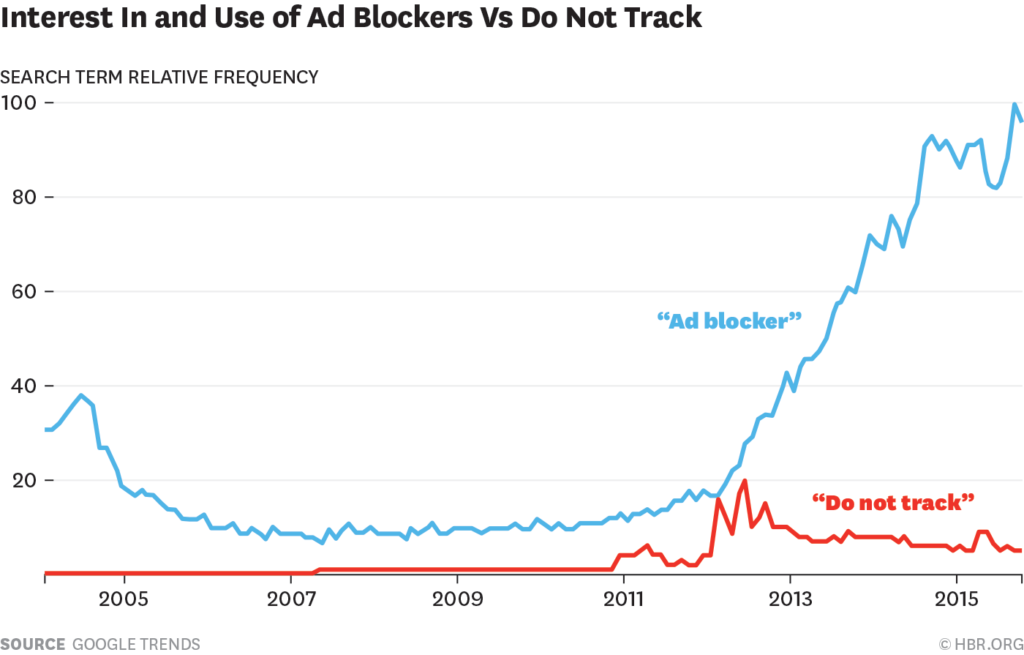
First, soon as it was clear that Do Not Track was a fail, ad blocking took off. You can see that in this Google Trends graph†††, published in Ad Blockers and the Next Chapter of the Internet (5 November 2015 in Harvard Business Review):
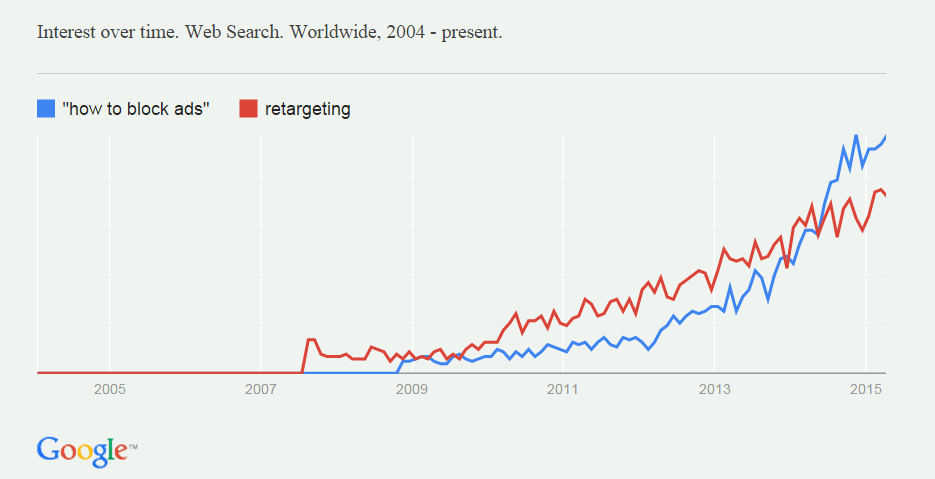
Next, ad searches for “how to block ads” rose right in step with searches for retargeting, which is the most obvious evidence that advertising is following you around:
You can see that correlation in this Google Trends graph in Don Marti’s Ad Blocking: Why Now, published by DCN (the online publishers’ trade association) on 9 July 2015:
Measures of how nearly all of us continue to hate tracking were posted by Dr. Johnny Ryan (@johnnyryan) in PageFair last September. In that post, he reports on a PageFair “survey of 300+ publishers, adtech, brands, and various others, on whether users will consent to tracking under the GDPR and the ePrivacy Regulation.” Bear in mind that the people surveyed were industry insiders: people you would expect to exaggerate on behalf of continued tracking.
Here’s one result:
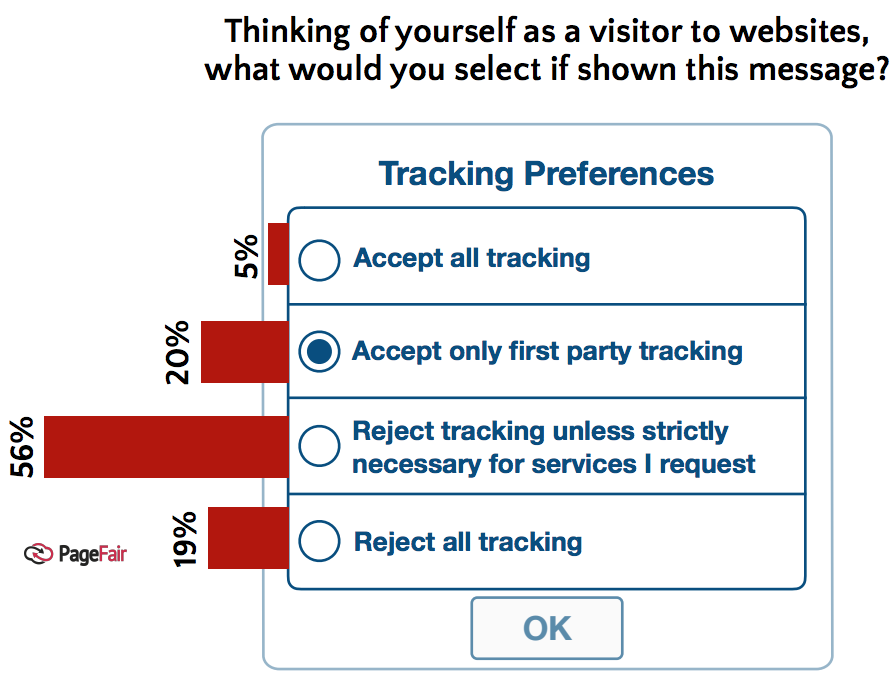
Johnny adds, “Only a very small proportion (3%) believe that the average user will consent to ‘web-wide’ tracking for the purposes of advertising (tracking by any party, anywhere on the web).” And yet the same survey reports “almost a third believe that users will consent if forced to do so by tracking walls,” that deny access to a website unless a visitor agrees to be tracked.”
He goes on to add, “However, almost a third believe that users will consent if forced to do so by ‘tracking walls”, that deny access to a website unless a visitor agrees to be tracked. Tracking walls, however, are prohibited under Article 7 of the GDPR, the rules of which are already formalised and will apply in law from late May 2018.[3] “
Which means that the general plan by the “interactive” advertising business is to put up those walls anyway, on the assumption that people will think they won’t get to a site’s content without consenting to tracking. We can read that in the subtext of IAB Europe‘s Transparency and Consent Framework, a work-in-progress you can follow here on Github., and read unpacked in more detail at AdvertisingConsent.eu.
So, to sum all this up, so far online what we have for privacy are: 1) popular but woefully inadequate ad blocking and tracking protection add-ons in our browsers; 2) a massively interesting regulation called the GDPR…
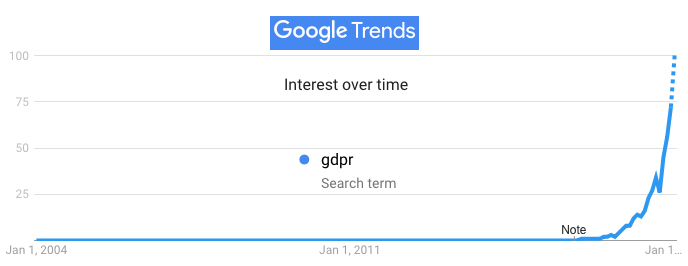
… and 3) plans by privacy violators to obey the letter of that regulation while continuing to violate its spirit.
So how do we fix this on the personal side? Meaning, what might we have for clothing and shelter, now that regulators and failed regulatory captors are duking it out in media that continue to think all the solutions to our problems will come from technologies and social signals other than our own?
Glad you asked. The answers will come in our next three posts here. We expect those answers to arrive in the world and have real effects—for everyone except those hellbent on tracking us—before the 25 May GDPR deadline for compliance.
† From Beyond ad blocking—the biggest boycott in human history: “According to PageFair’s 2017 Adblock Report, at least 615 million devices now block ads. That’s larger than the human population of North America. According to GlobalWebIndex, 37% of all mobile users, worldwide, were blocking adsby January of last year, and another 42% would like to. With more than 4.6 billion mobile phone usersin the world, that means 1.7 billion people are blocking ads already—a sum exceeding the population of the Western Hemisphere.”
†† It was plain old non-tracking-based advertising that not only only sponsored publishing and other ad-suported media, but burned into people’s heads nearly every brand you can name. After a $trillion or more has been spent chasing eyeballs, not one brand known to the world has been made by it. For lots more on all this, read everything you can by Bob Hoffman (@AdContrarian) and Don Marti (@dmarti).
††† Among the differences between the graph above and the current one—both generated by the same Google Trends search—are readings above zero in the latter for Do Not Track prior to 2007. While there are results in a search for “Do Not Track” in the 2004-2006 time frame, they don’t refer to the browser header approach later branded and popularized as Do Not Track.
Also, in case you’re reading this footnote, the family at the top is my father‘s. He’s the one on the left. The location was Niagara Falls and the year was 1916. Here’s the original. I flipped it horizontally so the caption would look best in the photo.