Just in case you feel safe with Twitter

Just got a press release by email from David Rosen (@firstpersonpol) of the Public Citizen press office. The headline says “Historic Grindr Fine Shows Need for FTC Enforcement Action.” The same release is also a post in the news section of the Public Citizen website. This is it:
WASHINGTON, D.C. – The Norwegian Data Protection Agency today fined Grindr $11.7 million following a Jan. 2020 report that the dating app systematically violates users’ privacy. Public Citizen asked the Federal Trade Commission (FTC) and state attorneys general to investigate Grindr and other popular dating apps, but the agency has yet to take action. Burcu Kilic, digital rights program director for Public Citizen, released the following statement:
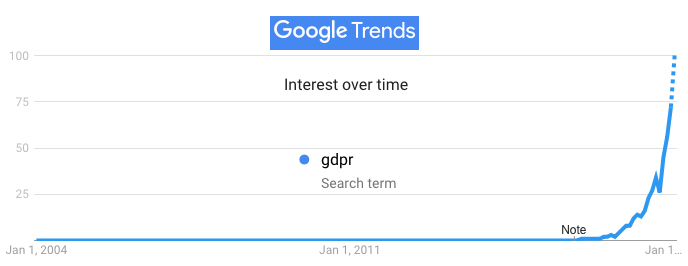
“Fining Grindr for systematic privacy violations is a historic decision under Europe’s GDPR (General Data Protection Regulation), and a strong signal to the AdTech ecosystem that business-as-usual is over. The question now is when the FTC will take similar action and bring U.S. regulatory enforcement in line with those in the rest of the world.
“Every day, millions of Americans share their most intimate personal details on apps like Grindr, upload personal photos, and reveal their sexual and religious identities. But these apps and online services spy on people, collect vast amounts of personal data and share it with third parties without people’s knowledge. We need to regulate them now, before it’s too late.”
The first link goes to Grindr is fined $11.7 million under European privacy law, by Natasha Singer (@NatashaNYT) and Aaron Krolik. (This @AaronKrolik? If so, hi. If not, sorry. This is a blog. I can edit it.) The second link goes to a Public Citizen post titled Popular Dating, Health Apps Violate Privacy.
In the emailed press release, the text is the same, but the links are not. The first is this:
https://default.salsalabs.org/T72ca980d-0c9b-45da-88fb-d8c1cf8716ac/25218e76-a235-4500-bc2b-d0f337c722d4
The second is this:
https://default.salsalabs.org/Tc66c3800-58c1-4083-bdd1-8e730c1c4221/25218e76-a235-4500-bc2b-d0f337c722d4
Why are they not simple and direct URLs? And who is salsalabs.org?
You won’t find anything at that link, or by running a whois on it. But I do see there is a salsalabs.com, which has “SmartEngagement Technology” that “combines CRM and nonprofit engagement software with embedded best practices, machine learning, and world-class education and support.” since Public Citizen is a nonprofit, I suppose it’s getting some “smart engagement” of some kind with these links. PrivacyBadger tells me Salsalabs.com has 14 potential trackers, including static.ads.twitter.com.
My point here is that we, as clickers on those links, have at best a suspicion about what’s going on: perhaps that the link is being used to tell Public Citizen that we’ve clicked on the link… and likely also to help target us with messages of some sort. But we really don’t know.
And, speaking of not knowing, Natasha and Aaron’s New York Times story begins with this:
The Norwegian Data Protection Authority said on Monday that it would fine Grindr, the world’s most popular gay dating app, 100 million Norwegian kroner, or about $11.7 million, for illegally disclosing private details about its users to advertising companies.
The agency said the app had transmitted users’ precise locations, user-tracking codes and the app’s name to at least five advertising companies, essentially tagging individuals as L.G.B.T.Q. without obtaining their explicit consent, in violation of European data protection law. Grindr shared users’ private details with, among other companies, MoPub, Twitter’s mobile advertising platform, which may in turn share data with more than 100 partners, according to the agency’s ruling.
Before this, I had never heard of MoPub. In fact, I had always assumed that Twitter’s privacy policy either limited or forbid the company from leaking out personal information to advertisers or other entities. Here’s how its Private Information Policy Overview begins:
You may not publish or post other people’s private information without their express authorization and permission. We also prohibit threatening to expose private information or incentivizing others to do so.
Sharing someone’s private information online without their permission, sometimes called doxxing, is a breach of their privacy and of the Twitter Rules. Sharing private information can pose serious safety and security risks for those affected and can lead to physical, emotional, and financial hardship.
On the MoPub site, however, it says this:
MoPub, a Twitter company, provides monetization solutions for mobile app publishers and developers around the globe.
Our flexible network mediation solution, leading mobile programmatic exchange, and years of expertise in mobile app advertising mean publishers trust us to help them maximize their ad revenue and control their user experience.
The Norwegian DPA apparently finds a conflict between the former and the latter—or at least in the way the latter was used by Grinder (since they didn’t fine Twitter).
To be fair, Grindr and Twitter may not agree with the Norwegian DPA. Regardless of their opinion, however, by this point in history we should have no faith that any company will protect our privacy online. Violating personal privacy is just too easy to do, to rationalize, and to make money at.
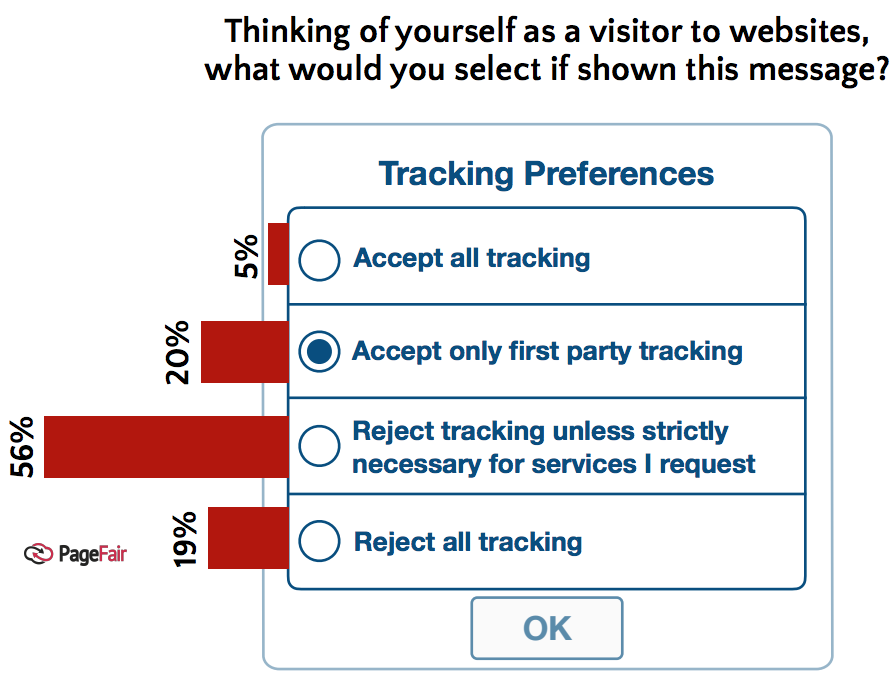
To start truly facing this problem, we need start with a simple fact: If your privacy is in the hands of others alone, you don’t have any. Getting promises from others not to stare at your naked self isn’t the same as clothing. Getting promises not to walk into your house or look in your windows is not the same as having locks and curtains.
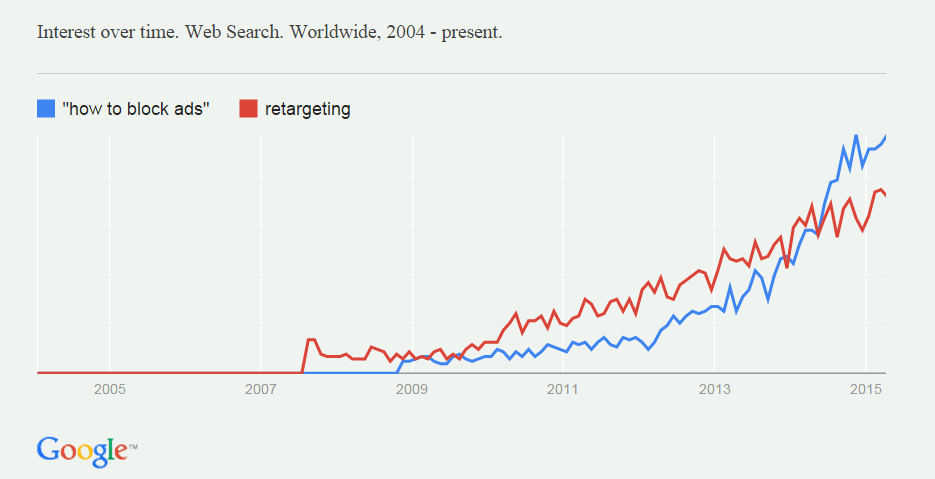
In the absence of personal clothing and shelter online, or working ways to signal intentions about one’s privacy, the hands of others alone is all we’ve got. And it doesn’t work. Nor do privacy laws, especially when enforcement is still so rare and scattered.
Really, to potential violators like Grindr and Twitter/MoPub, enforcement actions like this one by the Norwegian DPA are at most a little discouraging. The effect on our experience of exposure is still nil. We are exposed everywhere, all the time, and we know it. At best we just hope nothing bad happens.
The only way to fix this problem is with the digital equivalent of clothing, locks, curtains, ways to signal what’s okay and what’s not—and to get firm agreements from others about how our privacy will be respected.
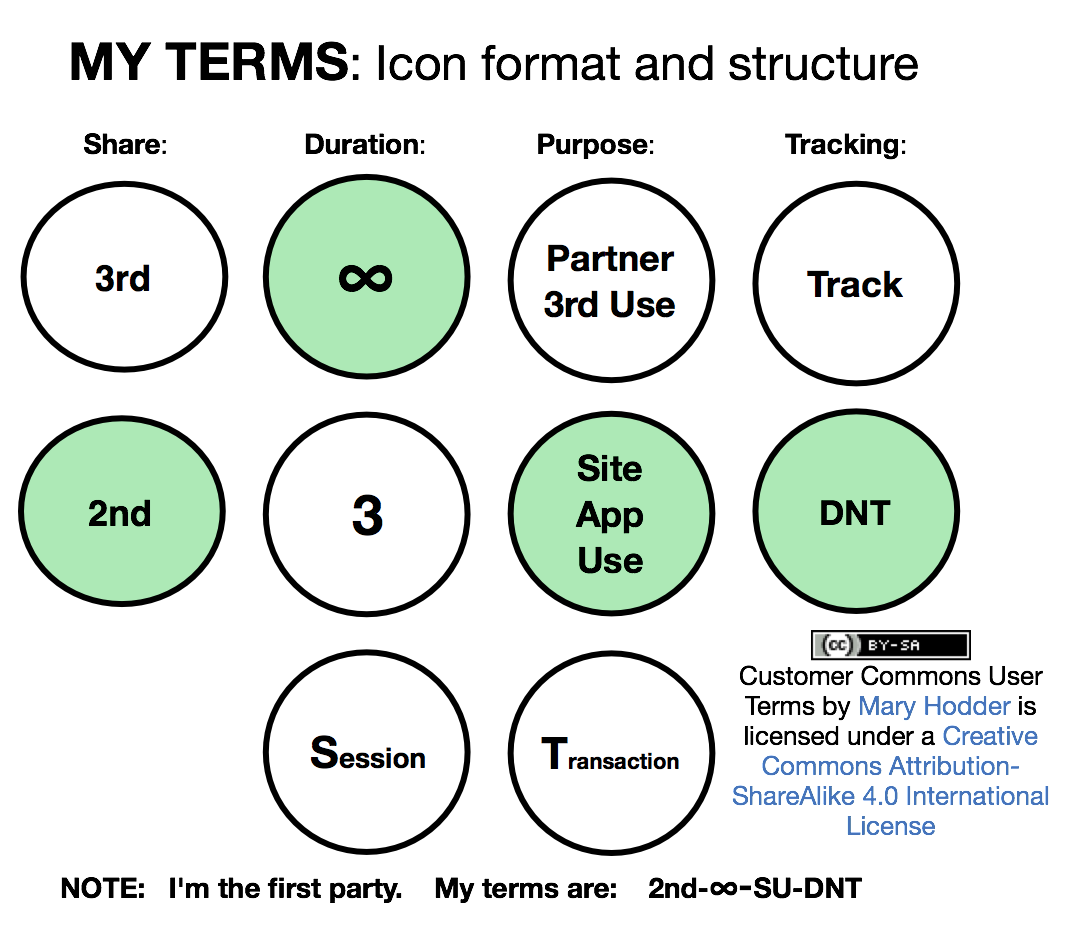
At Customer Commons, we’re starting with signaling, specifically with first party terms that you and I can proffer and sites and services can accept.
The first is called P2B1, aka #NoStalking. It says “Just give me ads not based on tracking me.” It’s a term any browser (or other tool) can proffer and any site or service can accept—and any privacy-respecting website or service should welcome.
Making this kind of agreement work is also being addressed by IEEE7012, a working group on machine-readable personal privacy terms.
Now we’re looking for sites and services willing to accept those terms. How about it, Twitter, New York Times, Grindr and Public Citizen? Or anybody.
DM us at @CustomerCommons and we’ll get going on it.


























.jpg){kind=link}