Bringing manners to marketing
The Cluetrain Manifesto was a success, and remains so, because it gives lessons in manners to marketing. Thus Cluetrain is also highly sourced by manners-minded marketing folk, who have eagerly leveraged Cluetrain‘s first thesis: “markets are conversations.”
It is now almost fourteen years since the Cluetrain website went up, thirteen since the original book came out, and three since the 10th anniversary edition hit the streets.Here are some stats, as of today:
- “Cluetrain,” a word that did not exist before 1999, appears in 9,689 books
- “cluetrain“, “#cluetrain“, “cluetrainmanifesto” “thecluetrainmanifesto” and other tags get tweeted every day, sometimes many times per day
- Searches for “cluetrain” bring up about a half million results on Google
- Add “conversation” and the results top a million
- “conversational marketing” brings up about a hundred thousand results
Most of those results are generated by polite marketers. Unfortunately, there are still too many marketers of the rude sort. To these marketers, customers are “targets” to be “captured,” “controlled,” “managed,” “locked in” and otherwise treated without the full respect we grant human beings we interact with personally, in actual conversation. These marketers are the types about which the great Bill Hicks said this:
That was in 1992. Imagine what Bill would say about marketing at the dawn of 2013. Here’s how that picture looks to Luma Partners:
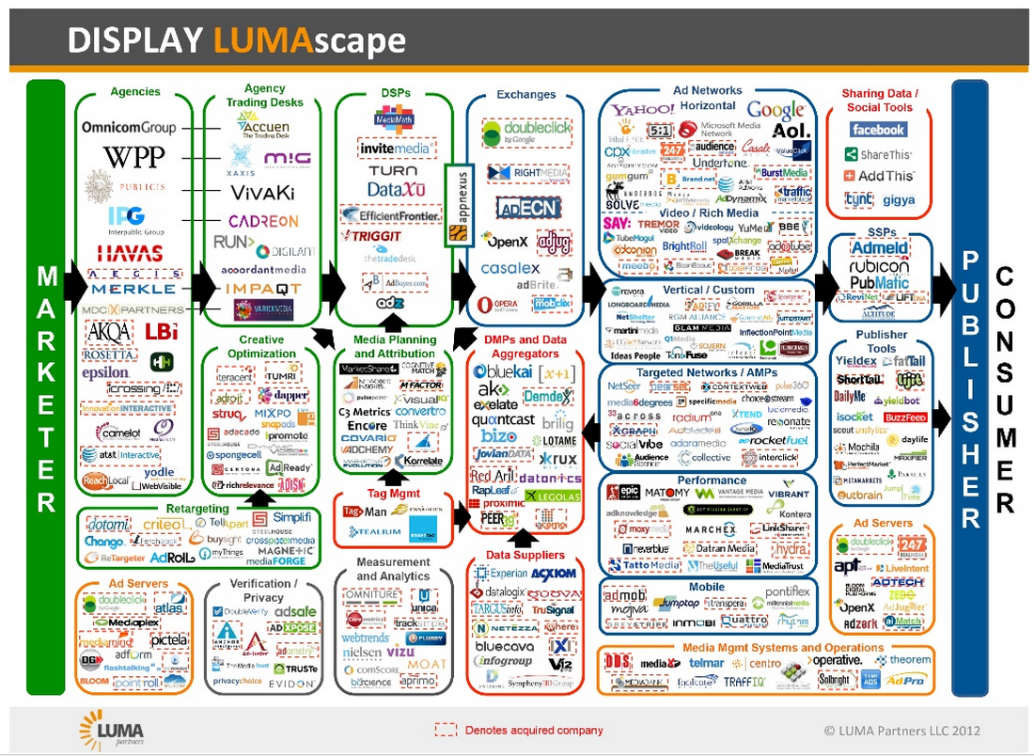
Rotate that thing 90° to the right, so the movement is top to bottom, rather than left to right. Then think about the combined weight of all that marketing, pressing down on the consumer.
No doubt some small pieces of that great mess of marketing are respectful of the consumer. And some of these categories (such as, for example, “publisher tools”) are comprised of companies providing tools for actually interacting with customers, rather than just for targeting at consumers. (The distinction is critical. Doug Rauch, retired President of Trader Joe’s, calls consumer “a statistical category.” He says, “We say customer, person, or individual.”)
Cluetrain was written in 1999, when — compared to the above — digital marketing was still in its Precambrian stage, and was essentially a declaration of independence from marketing. As Jakob Nielsen told me later, Cluetrain‘s four authors essentially defected from marketing and sided with markets against marketing. This was made clear by the Manifesto’s alpha clue, which was written by Chris Locke. Though less quoted than the 95 numbered theses below, it remains the most important:

So, in 2006, I launched ProjectVRM to foster development of tools and services that would provide the reach to exceed marketing’s grasp. As of today there are dozens of VRM developers working on the customers’ side.
We have a model for that reach in the brick & mortar world, in the form of well-mannered one-to-one interactions between vendors and customers, in what the CRM business calls the buy cycle and the own cycle. As I wrote here, “Nobody from a store on Main Street would follow you around with a hand in your pocket and tell you ‘I’m only doing this so I can give you a better shopping experience.'” But online, and through our mobile devices, we are being tracked like animals by a business that often rationalizes the (almost literal) hell out of it.
It would seem a lot worse if surveillance-fed “big data” advertising algorithms didn’t also suck at it, most of the time. One case in point: Facebook. Here is my Facebook profile picture and top-level data, plus some screen shots of ads Facebook has presented to me in the last few minutes:
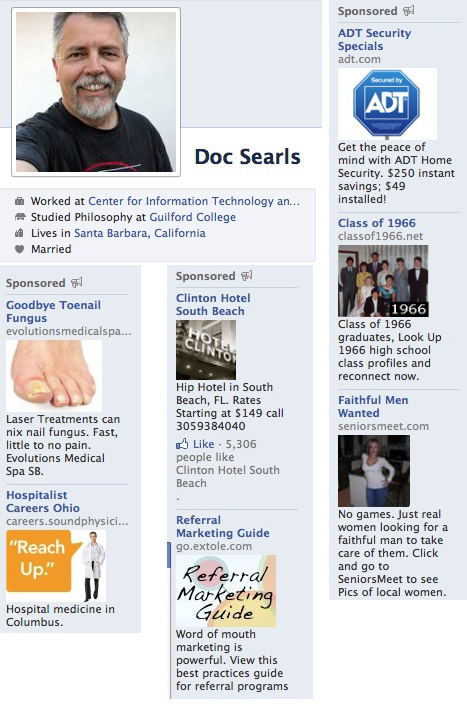
So, almost across the board, the ads I see on Facebook are rude, wrong, or both. And I’m sure, in this respect, that I’m no exception.
A couple years ago, the top guy at one of the advertising companies told me something interesting about Facebook and Google. He said they were extremely jealous of what the other could do with advertising, but that they could not do themselves — or, at least, not yet. Facebook was jealous of Google, he said, because Google could advertise all over the Web. And Google was jealous of Facebook, because Facebook could get far more personal with its advertising than Google could. Yet, because we are consumers of those companies’ services, rather than customers, we have no direct, money-backed, truly conversational mechanisms for giving them useful feedback. Such as, “Excuse me, but your manners really suck here.”
Although I am not a heavy Facebook user, I have been on the thing since 2006, and have hundreds of friends there. I am also a highly public person and not hard to figure out if you want to get personal with me. Yet I have never seen a personalized ad that appealed to me with anything I’d call accuracy. Once in awhile I’ll see an ad for something photographic, but I don’t know whether that’s because I do a lot of photography, or because the advertiser is carpet-bombing some large population, or… whatever. As Don Marti eloquently points out, the targeted individual in the system diagramed above doesn’t know what’s actually going on. Should he or she bother to care about an ad, the thought balloon over his or her head would say “I don’t know if your company is really spending a lot on advertising, or if you’re just targeting me.”
In Facebook and Google may be forced to ask permission to use personal data, The Guardian visits the prospect of regulatory relief. My problem with that approach is that it assumes that we, as poor “consumers,” are naturally weak. But I don’t think we are. I think we are strong, and only bound to get stronger. That’s why I invite everybody reading this to join Customer Commons, and to start using VRM tools and services. Let’s demonstrate genuine market power, for our good, for the health of the Internet we share, and to give real help to every business that wants to treat real customers with real respect.























